Mining the Web of HTML-embedded Product Data
Semantic Web Challenge @

News
 The proceedings are ready! See here.
The proceedings are ready! See here.- Winners of Round 1 results are: Task 1 - Team PMap from the National Institute of Advanced Industrial Science and Technology (AIST) and National Institute of Informatics (NII); and Task 2 - Team Rhinobird from Tongji University of China and Tencent. Many congratuations to the winners! Round 1 results here.
- 17 August 2020: the ground truth for both tasks are now released. Download them here: task 1 and task 2.
- 17 August 2020: the second round of competion has now ended. See Round 2 results here.
- 13 July 2020: the second round of competion is NOW OPEN! Due to popular demand, we decided to run a second round of competition. See details here.
- 22 June 2020: the validation set for the product classification task has been updated, removing labels not present in the training set. The test set is unchanged. This slightly affected the baseline performance, which is now updated too.
- 1 June 2020: Test datasets are released for both the product classification and matching tasks!
- 14 May 2020: In line with the ISWC2020 deadline extensions, we announce an extension of the submission deadlines of our event. System output submission is now 06 July 2020. Please see the 'Important Dates' section for details.
- 16 April 2020: We have released some example code for building your own training sets for the product matching task.
- 27 March 2020: Due to Covid-19, ISWC2020 has decided to go virtual. The same will apply to our event. The challenge will take place as planned and the schedule will stay unchanged. So please already start experimenting with the training and validation data, so that you are prepared for the release of the test set on 1 June.
- 16 March 2020: the training and validation sets for both tasks have been released. Please scroll down to the dataset section of each task for details. You can now start testing your systems!
- 02 March 2020: the first Call for Participation has beeen annouced. The Google discussion group is also open. Please join the discussion if you wish to take part in this event!
CEUR proceedings
CEUR link can be found here
| Title | Authors |
|---|---|
| MWPD2020: Semantic Web Challenge on Mining the Web of HTML-embedded Product Data | Ziqi Zhang, Christian Bizer, Ralph Peeters, Anna Primpeli |
| PMap: Ensemble Pre-training Models for Product Matchin | Natthawut Kertkeidkachorn, Ryutaro Ichise |
| A Pre-trained Matching Model Based on Self- and Inter-ensemble For Product Matching Task | Shiyao Xu, Shijia E, Li Yang, Yang Xiang |
| Bert with Dynamic Masked Softmax and Pseudo Labeling for Hierarchical Product Classification | Li Yang, Shijia E, Shiyao Xu, Yang Xiang |
| ProBERT: Product Data Classification with Fine-tuning BERT Mode | Hamada Zahera, Mohamed Sherif |
| ISCAS_ICIP at MWPD-2020 Task 1: Product Matching Based on Deep Entity Matching Frameworkss | Cheng Fu, Tianshu Wang, Hao Nie, Xianpei Han, Le Sun |
| Language Model CNN-driven Similarity Matching and Classification for HTML-embedded Product Data | Janos Borst, Erik Körner, Kobkaew Opasjumruskit, Andreas Niekler |
Workshop Program
Link to the conference general program here. The workshop comes under the name 'SW Challenge 3, Mining'. Note that registration may be required to view it. The workshop is divided into two 1-hour slots on two separate days.
Detailed workshop program schedule below
| 18:00 - 19:00 CET Thursday 05 Nov 2020 | |
|---|---|
| Introduction | The organisers |
| ISCAS_ICIP at MWPD-2020 Task 1: Product Matching Based on Deep Entity Matching Frameworks | Cheng Fu, Tianshu Wang, Hao Nie, Xianpei Han, Le Sun |
| Language Model CNN-driven Similarity Matching and Classification for HTML-embedded Product Data (TASK 1) | Janos Borst, Erik Körner, Kobkaew Opasjumruskit, Andreas Niekler |
| Language Model CNN-driven Similarity Matching and Classification for HTML-embedded Product Data (TASK 2) | Janos Borst, Erik Körner, Kobkaew Opasjumruskit, Andreas Niekler |
| Discussion | All |
| 14:00 - 15:00 CET Friday 06 Nov 2020 | |
|---|---|
| PMap: Ensemble Pre-training Models for Product Matching (TASK 1 Winner) | Natthawut Kertkeidkachorn, Ryutaro Ichise |
| Bert with Dynamic Masked Softmax and Pseudo Labeling for Hierarchical Product Classification (TASK 2 Winner) | Li Yang, Shijia E, Shiyao Xu, Yang Xiang |
| Summary and prizes | All |
Overview
Recent years have seen significant use of semantic annotations in the e-commerce domain, where online shops (e-shops) are increasingly adopting semantic markup languages to describe their products in order to improve their visibility. Statistics from the Web Data Commons project show that 37% of the websites covered by a large web crawl provide semantic annotations. 849,000 of these websites annotate product data using the schema.org classes product and offer. However, fully utilising such a gigantic data source still faces significant challenges. This is because the adoption of semantic markup practice has been generally shallow and to a certain extent inconsistent. For example, less than 10% of product instances are annotated with a category; categorisation systems used by different e-shops are highly inconsistent; the same products are offered on different websites, often presenting complementary and sometimes even conflicting information.
Addressing these challenges requires an orchestra of semantic technologies tailored to the product domain, such as product classification, product offer matching, and product taxonomy matching. Such tasks are also crucial elements for the construction of product knowledge graphs, which are used by large, cross-sectoral e-commerce vendors.
This challenge aims to benchmark methods and systems dealing with two fundamental tasks in e-commerce data integration: (1) product matching (task one) and (2) product classification (task two) . We develop datasets and resources to share with the community, in order to encourage and facilitate research in these directions.
Submission rounds
Round One between 01 June 2020 and 06 July 2020: Participating teams may choose to take part in either or both tasks. Winners of each task will be awarded 500 euro. This is partly sponsored by Peak Indicators.
Round Two between 13 July 2020 and 17 August 2020: Participating teams may choose to take part in either or both tasks. Participants in Round One are welcome to also take part in Round Two. They will also receive limited feedback (e.g., error types, results of different versions of their outputs) on their Round One submissions in order to help them further improve their system performance.
Both rounds use the same datasets. Participants in both rounds will be invited to write a paper describing their method and system and present (subject to a 'light-touch' review) their work at the SWC2020 event that is part of the ISWC2020 conference.
This challenge is organised by the University of Sheffield, the University of Mannheim, and Amazon.
Important Dates
| Date | Milestone |
|---|---|
| 05/06 Nov 2020 | Presentation at the ISWC conference |
Task One - Product Matching
Product matching deals with identifying product offers deriving from different websites that refer to the same real-world product. In this task, product matching is handled as a binary classification problem: given two product offers decide if they describe the same product (matching) or not (non-matching).
Background information
Product offers are published on the web together with some textual descriptions and are often accompanied by specification tables, i.e. HTML tables that contain specifications about the offer such as price or the country of origin. The syntactic, structural and semantic heterogeneity among the offers makes product matching a challenging task.
The Web Data Commons project has released in 2018 the WDC Product Data Corpus, the largest publicly available product data corpus originating from e-shops on the Web. The corpus consists of 26 million product offers originating from 70 thousand different e-shops. Exploiting the weak supervision found on the web in the form of product identifiers, such as GTINs or MPNs, product offers are grouped into 16 million clusters. The clusters can be used to derive training sets containing matching and non-matching pairs of offers. The derived sets can in turn be used to train the actual matching methods.
Data format
We offer the product data corpus in JSON format. Offers having the same cluster ID attribute are considered to describe the same real-world product while different cluster IDs signify different products. The grouping of offers into clusters is subject to some degree of noise (approx. 7%) as it has been constructed using a heuristic to cleanse the product identifiers, such as GTINs and MPNs, found on the Web. Every JSON object describing an offer has the following JSON properties:
- id: Unique identifier of an offer (random integer) (DO NOT USE AS FEATURE!)
- cluster_id: The heuristically assigned identifier of the cluster to which an offer belongs (DO NOT USE AS FEATURE!)
- category: One of 25 product categories the product was assigned to
- title: The product offer title
- description: The product offer description
- brand: The product offer brand
- price: The product offer price
- specTableContent: The specification table content found on the website of the product offer as one string
- keyValuePairs: The key-value pairs that were extracted from the specification tables.
The following example shows what a product offer looks like in JSON format:
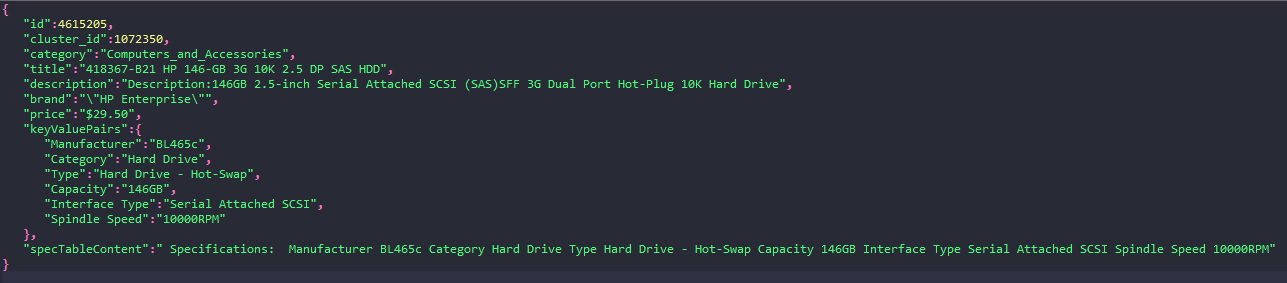
We also offer an example of a training set that we derived from the corpus. The training set contains pairs of matching and non-matching offers from the category computer products. You can use this example set for training your matchers. The example training set contains 68K offer pairs from 772 distinct products (clusters of offers). These products will only partly overlap with the products in the test set that we will release in June. We thus suggest that participating teams construct their own training sets from the corpus having higher coverage of distinct products. Every JSON object in the training set describes a pair of offers (left offer - right offer) using the offer attributes listed above together with their corresponding matching label.
The following example shows what a product offer pair looks like in JSON format:
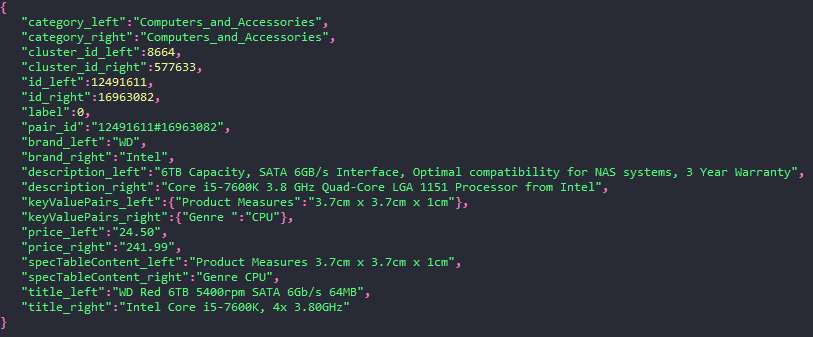
The validation and test sets will also be released in JSON format. The validation set has the same structure as the training set while the test set will be released without the label column. Both sets are constructed from offer pairs from the category Computers and Accessories. All pairs of offers in the validation and test sets are manually labeled. Using the example training set to train deepmatcher, a state-of-the-art matching method, achieves 90.8% F1 on the validation set. However, the test set of this challenge will be more difficult as (amongst other challenges) it will contain offers from clusters (products) that are not contained either in the training set or in the validation set.
Additional information about the assembly of the example training set, the validation set, as well as the results of baseline experiments using both artefacts are found here.
Round 2 Hints
For Round 2 we publish some information about the composition of the test set. More specifically we will also provide each team of Round 1 with Precision, Recall and F1 values for 5 meta-classes that product pairs in the test set can be categorized into. We use specific vocabulary when refering to these classes:
- "Known products" means products from clusters that have training data in the provided training set
- "New products" are contained in the overall corpus but not in the provided training set
- "High and low similarity" refers to jaccard similarity on titles
- "Very hard case" means either highly similar negatives or dissimilar positives
The amount of positives and negatives of each of the classes found in the test set can be seen after each class name in the list below. The remaining 1000 product pairs of the test set not directly part of the 5 meta-classes could mostly be assigned to the class "very hard cases for known products" but are not as similar/dissimilar on the titles as the very hard cases. A small rest are new products not belonging into any of the five meta-classes.
The five meta-classes are:
- New products with high similarity with known products (25 pos / 75 neg)
- New products with low similarity with known products (25 pos / 75 neg)
- Known products with introduced typos (100 pos)
- Known products with dropped tokens (100 pos)
- Very hard cases for known products (25 pos / 75 neg)
A small example set containing pairs and ground truth for the five classes can be found in the Data download section below. The "sampling" column in this dataset provides information about the meta-class to which an example belongs. Note that the examples for "known products with introduced typos" and "known products with dropped tokens" are actually modified versions of the examples for the "very hard cases for known products" class, allowing for an inspection of the extent of such modifications.
Data download
- Product Data Corpus (~16M offers)
- Example training Set (~68K offer pairs)
- Validation Set (1.1K offer pairs)
- Test set (1500 offer pairs)
- Test set (1500 offer pairs) with ground truth
- Example Set Feedback Meta-Classes (24 offer pairs)
Evaluation metric
Precision, Recall and F1 score on the positive class (matching) will be calculated. The F1 score on the positive class (matching) will be used to rank the participating systems.
Tools
Use your favourite JSON parser to parse the datasets. We suggest using the Python pandas package to parse each file into a dataframe:
import pandas as pd
df = pd.read_json(filename, lines=True)Task Two - Product Classification
Product classification deals with assigning predefined product category labels to product instances (e.g., iPhone X is a ‘SmartPhone’, and also ‘Electronics’). In this task, we will be using the top 3 classification levels of the GS1 Global Product Classification scheme to classify product instances.
Background information
Same products are often sold on different websites, which generally organise their products into certain categorisation systems. However, such product categorisations differ significantly for different websites, even if they sell similar product ranges. This makes it difficult for product information integration services to collect and organise product offers on the Web.
An increasing number of studies have been carried out for automated product classification based on the product offer information made available on the Web. Initiatives such as the Rakuten Data Challenge were also created to develop benchmarks for such tasks. However, the majority of such datasets have been created based on a single source of website, and using a flat classification structure.
The Web Data Commons project released in 2014 the first product classification dataset collected from multiple websites, annotated with three levels of classification labels. This dataset has been extended and is now used for the product classification task in this challenge.
Data format
Data are provided in JSON, with each line describing one product instance using the following schema. Each product will have three classification labels, corresponding to the three GS1 GPC classification levels.
- ID: an arbitrary ID of the product
- Name: the name of the product (an empty string if unavailable)
- Description: the description of the product (truncated to a maximum of 5,000 characters. Can be an empty string if unavailable)
- CategoryText: website-specific product category, or breadcrum (an empty string if unavailable)
- URL: the original webpage URL of the product
- lvl1: the level 1 GS1 GPC classification (i.e., classification target)
- lvl2: the level 2 GS1 GPC classification (i.e., classification target)
- lvl3: the level 3 GS1 GPC classification (i.e., classification target)
An example screenshot (formatted as 'pretty-print') is shown below.

Data download
- Training set (contains approx. 10k instances)
- Validation set (contains approx. 3k instances)
- Test set (contains approx. 3k instances)
- Test set (contains approx. 3k instances) with ground truth
Evaluation metric
For each classification level, the standard Precision, Recall and F1 will be used and a Weighted-Average macro-F1 will be calculated over all classes. Then the average of the WAF1 of the three levels will be calculated and used to rank the participating systems.
A basline is developed to support participants. This is the same as that used in the Rakuten Data Challenge. Implementation of this baselin is available in our GitHub repository (see below). Details of the baseline:
- Based on the FastText algorithm
- Uses only product titles/names, which are all lowercased and lemmatised (using NLTK)
- Does not use pre-trained word embeddings
An overview of the performance of the baseline and its variants on the validation set are shown below for reference (note that only the figures marked in yellow are used for comparison with participating systems). Details (including P, R, F1 for each level of classification) of these results can be found here
| Model | Weighted Avg. P, R, F1 | Macro Avg. P, R, F1 | ||||
|---|---|---|---|---|---|---|
| Baseline | 85.553 | 84.167 | 84.255 | 66.164 | 60.709 | 61.542 |
| Baseline + word embeddings (CBOW, see below) | 86.498 | 86.000 | 85.734 | 70.639 | 63.925 | 65.551 |
| Baseline + word embeddings (Skipgram, see below) | 85.453 | 84.911 | 84.575 | 70.574 | 62.740 | 64.693 |
Tools
Our GitHub website is currently being updated and will be ready by 16 March 2016. It will provide code for:
- Parsing the input datasets
- Scoring the output prepared in the required format (see the Submission section for details)
- Baseline, which is a FastText implementation same as that in the Rakuten Data Challenge
Details can be found on the corresponding GitHub page.
Other Resources
Participants are free to decide if they would like to use any of these resources to support their development
To support the development of systems we have created language resources that may be useful for both tasks. We processed the 2017 November WDC crawl of all entities that are an instance of http://schema.org/Product or http://schema.org/Offer, and indexed the products (English only) using Solr 7.3.0. We then exported the descriptions (if available) of these products and used the data (some heuristic-based filtering is applied, resulting in over 150 million products) to train word embeddings using the Gensim implementation of Word2Vec. We share the following resources that can be used by participants:
- The text corpus containing the above product descriptions (11GB)
- The word embeddings trained using the above corpus (lowercased). Both continuous bag-of-words and skipgram models are available, and are trained using Gensim 3.4.0. Available in the following two formats:
- Gensim format. This is optimised for speedy loading of the model and is also more memory-efficient. Use the code
to load the model.gensim.models.KeyedVectors.load([embedding_file_ending_with_bin]], mmap='r') - Word2Vec non-binary (text) format. This is needed if you want to run the FastText baseline. However, this model file is not optimised for memory usage or speed.
The effect of the word embeddings is demonstrated in the table in the Section Evaluation metrics
Submission
Round 2 submission is now open. Please find details of the required submissions and their formats below.
System outputs
For both tasks, please name your submission in the following pattern: [Team]_[Task1/2] where 'Team' should be a short name to identify your team. This will be used to list participant results. 'Task1/2' should be either 'Task1' or 'Task2' depending on which task you participate in. If you take part in both tasks, please make two separate submissions.
Task one - product matching
Submit your output as a single, zip file through this Google form link. The zip file must contain a single CSV file conforming to the following format:
- One offer pair on each row
- Comma separated
- Column 1=left offer id, column 2=right offer id and column 3=label (1 or 0)
An example for a predicted match and non-match is shown below:
123456,654321,1
123456,987654,0Task two - product classification
Submit your output as a single, zip file through this Google Form link. The zip file must contain a single CSV file comforming to the following format:
- One product instance on each row
- Comma separated
- Column 1=product ID as-is in the test set, column 2=Level 1 label, column 3=Level 2 label, and column 4=Level 3 label
- Use UTF-8 encoding
An example is available in the GitHub website. A dummy example is also shown in the following screenshot.

System description paper
Tentative deadline for submission: 23:59:59 Hawaiian Time 02 Sep 2020, submission link here.
Submissions of research articles to this event are based on participation only. Papers submitted must conform to the formatting requirements of the ISWC main conference, and must be within the range of 5-8 pages. Specifically, they must be either in PDF or HTML, formatted in the style of the Springer Publications format for Lecture Notes in Computer Science (LNCS). For HTML submission guidance, please see the HTML submission guide.
Papers submitted will undergo a brief review process for quality assurance. Where appropriate, feedback may be provided to authors for consideration to improve the quality of their submissions.
The final accepted papers will be distributed to conference attendees and also as a volume of CEUR-WS. By submitting a paper, the authors accept the CEUR-WS publishing rules.
Competition results
Round 1 Results on the Test set
| Task 1 (product matching) | Task 2 (product classification) | ||||||
|---|---|---|---|---|---|---|---|
| Team/System | Precision | Recall | F1 (positive pairs only) | Team/System | Precision | Recall | F1 (avg. weighted*) |
| PMap | 82.04 | 90.48 | 86.05 | Rhinobird | 89.01 | 89.04 | 88.62 |
| Rhinobird | 82.86 | 88.38 | 85.53 | Team ISI | 87.16 | 86.85 | 86.54 |
| ASVinSpace | 86.20 | 82.10 | 84.10 | ASVinSpace | 86.96 | 86.30 | 86.10 |
| ISCAS-ICIP | 83.89 | 81.33 | 82.59 | Megagon | 84.98 | 84.98 | 84.98 |
| Megagon | 82.69 | 65.52 | 73.11 | Baseline FastText | 85.55 | 84.17 | 84.26 |
| Baseline DeepMatcher | 70.89 | 74.67 | 72.73 | DICE_UPB | 85.30 | 81.49 | 81.84 |
| Team ISI | 78.44 | 57.52 | 66.37 | ||||
* Average weighted macro F1 of all three levels. This can result in an F-score that is not between precision and recall.
Round 2 Results on the Test set
| Task 1 (product matching) | Task 2 (product classification) | ||||||
|---|---|---|---|---|---|---|---|
| Team/System | Precision | Recall | F1 (positive pairs only) | Team/System | Precision | Recall | F1 (avg. weighted*) |
| Rhinobird | 80.63 | 92.00 | 85.94 | Rhinobird | 88.97 | 88.72 | 88.43 |
| ISCAS-ICIP | 85.77 | 84.95 | 85.36 | ||||
| Baseline DeepMatcher | 70.89 | 74.67 | 72.73 | Baseline FastText | 85.55 | 84.17 | 84.26 |
Overall Results
| Task 1 (product matching) | Task 2 (product classification) | ||||||
|---|---|---|---|---|---|---|---|
| Team/System | Precision | Recall | F1 (positive pairs only) | Team/System | Precision | Recall | F1 (avg. weighted*) |
| PMap | 82.04 | 90.48 | 86.05 | Rhinobird | 89.01 | 89.04 | 88.62 |
| Rhinobird (R2) | 80.63 | 92.00 | 85.94 | Rhinobird (R2) | 88.97 | 88.72 | 88.43 |
| Rhinobird | 82.86 | 88.38 | 85.53 | Team ISI | 87.16 | 86.85 | 86.54 |
| ISCAS-ICIP (R2) | 85.77 | 84.95 | 85.36 | ASVinSpace | 86.96 | 86.30 | 86.10 |
| ASVinSpace | 86.20 | 82.10 | 84.10 | Megagon | 84.98 | 84.98 | 84.98 |
| ISCAS-ICIP | 83.89 | 81.33 | 82.59 | Baseline FastText | 85.55 | 84.17 | 84.26 |
| Megagon | 82.69 | 65.52 | 73.11 | DICE_UPB | 85.30 | 81.49 | 81.84 |
| Baseline DeepMatcher | 70.89 | 74.67 | 72.73 | ||||
| Team ISI | 78.44 | 57.52 | 66.37 | ||||
* R2 indicates results obtained by the same team in Round 2. Otherwise, results are obtained in Round 1
Conference presentation
Details of the presentation schedule will be published here in due course. Prizes for the winner of Round One will be handed out during the event.
Organizing committee
To contact the organising committee please use the Google discussion group here
Chair
- Dr Ziqi Zhang (Information School, The University of Sheffield)
- Prof. Christian Bizer (Institute of Computer Science and Business Informatics, The Mannheim University)
Other PC members
- Dr Haiping Lu (Department of Computer Science, The University of Sheffield)
- Dr Jun Ma (Amazon Inc. Seattle, US)
- Prof. Paul Clough (Information School, The University of Sheffield & Peak Indicators)
- Ms Anna Primpeli (Institute of Computer Science and Business Informatics, The Mannheim University)
- Mr Ralph Peeters (Institute of Computer Science and Business Informatics, The Mannheim University)
- Mr. Abdulkareem Alqusair (Information School, The University of Sheffield)